
Distrbuted Communication in PyTorch
This is the second part of a 3-part series covering multiprocessing, distributed communication, and distributed training in PyTorch.
In this article we will take a look at the distribued communication features in PyTorch via the torch.distributed module.
What torch.distributed is
The package provides means of communication between processes running on different computation nodes, either on the same machine or on different machines (e.g. in a cluster). DistributedDataParallel is built on top of torch.distributed and provides a convenient way to run models on multiple GPUs.
Initialization
The initialization phase may consist of 2 steps: choosing a backend, and setting up the communication.
Backends
torch.distributed supports three backends: Gloo, NCCL, and MPI. Gloo and NCCL are included in torch.distributed; NCCL is included only when building with CUDA. MPI can only be used by building PyTorch from source on systems with MPI installed. It is recommended to use NCCL for distributed GPU applications, and Gloo for distributed CPU applications.
NOTE: Use the correct network interface. NCCL and Gloo will try to find the right network interface to use. If it is not the correct one, you can specify it by setting the environment variable NCCL_SOCKET_IFNAME or GLOO_SOCKET_IFNAME, depending on the backend you are using.
Setting up the connection
One must initialize the communication using torch.distributed.init_process_group before using any other function in torch.distributed. The syntax is:
torch.distributed.init_process_group(
backend,
init_method=None,
timeout=datetime.timedelta(seconds=1800),
world_size=-1,
rank=-1,
store=None,
group_name='',
pg_options=None
)
The backend parameter can take one of the following values: 'gloo', 'nccl', or 'mpi'. rank is the rank, or index, of the current process, with rank 0 usually being the master process. world_size is the number of total processes.
There are two ways to initialize the process group:
- Create a distributed key-value store:
HashStore(can only be used within a process),TCPStore, orFileStore; and then pass the store, world size, and rank toinit_process_group. - Specify
init_method(a URL string) which indicates where/how to discover peers. Optionally specifyrankandworld_size, or encode all required parameters in the URL and omit them.
For the second—and also more common—way, we will take a look at the two supported initialization methods, using TCP and shared file system:
- Shared file system: If there exists a file system that is visible to all nodes, we can use it to initialize the process group.
import torch.distributed as dist
dist.init_process_group(backend, init_method='file:///mnt/nfs/sharedfile',
world_size=4, rank=args.rank)
I have never seen this in practice though. Maybe I haven’t seen enough.
- TCP:
The more common way to initialize the process group is to use TCP. We can encode some or all information in a URL string, or set the environment variables
MASTER_ADDRandMASTER_PORTfor each node. The second method works because if not specified (andstoreisNone), theinit_methodwill be set toenv://by default.
import torch.distributed as dist
import os
# Style 1: URL string
dist.init_process_group(backend, init_method='tcp://10.1.1.20:23456',
rank=rank, world_size=4)
# Style 2: environment variables
os.environ['MASTER_ADDR'] = '10.1.1.20'
os.environ['MASTER_PORT'] = '23456'
dist.init_process_group(backend, rank=rank, world_size=4)
Putting it all together
The example below shows how to initialize the process group using TCP on multiple processes on the same machine. We create the processes using torch.multiprocessing.spawn.
import os
import torch
import torch.multiprocessing as mp
import torch.distributed as dist
def main(rank, size):
dist.init_process_group('gloo', rank=rank, world_size=size)
print(f'Worker {rank} ready')
if __name__ == "__main__":
# Setup
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '23456'
# Spawn 4 processes
mp.spawn(main, args=(4,), nprocs=2, join=True)
Worker 0 ready
Worker 1 ready
Worker 3 ready
Worker 2 ready
The master address and port specifies the address of the rank 0 node—that is accessible to all other nodes—and an open port that can be used to communicate with the master.
Communication
Once initialization is completed, we are ready to write a distributed application. A vital part of which is cross-process communication, and by communicating we mean sending and receiving tensors.
Point-to-point communication
To send and receive a tensor, we can use the send and recv functions.
# World size 2
def main(rank, size):
dist.init_process_group('gloo', rank=rank, world_size=size)
if rank == 0:
tensor = torch.randn(4, 4)
# Send the tensor to rank 1
dist.send(tensor=tensor, dst=1)
else:
# Receive a tensor from rank 0
tensor = torch.zeros(4, 4) # Placeholder, the shape has to match
dist.recv(tensor=tensor, src=0)
print("Received tensor:", tensor)
send and recv are blocking functions. Both processes are blocked until the tensor is received. To send and receive tensors in a non-blocking manner, we can use the isend and irecv functions. “i” is shorthand for “immediate”. These two functions return a distributed request object. We can then wait for the communication to complete using the wait function.
# World size 2
def main(rank, size):
dist.init_process_group('gloo', rank=rank, world_size=size)
if rank == 0:
tensor = torch.randn(4, 4)
# Send the tensor to rank 1
req = dist.isend(tensor=tensor, dst=1)
else:
# Receive a tensor from rank 0
tensor = torch.zeros(4, 4) # Placeholder, the shape has to match
req = dist.irecv(tensor=tensor, src=0)
# do other work
req.wait()
if rank == 1:
print("Received tensor:", tensor)
We should neither modify the sent tensor nor access the received tensor until the communication is complete. Doing so will result in undefined behavior.
Collective communication
The scalability of distributed computation is achieved by making use of collective communication. Collective communication involves multiple senders and/or receivers among a process group. Some common collective operations, in context of communicating tensors, include:
Broadcast: A tensor is broadcasted to all processes in the process group.
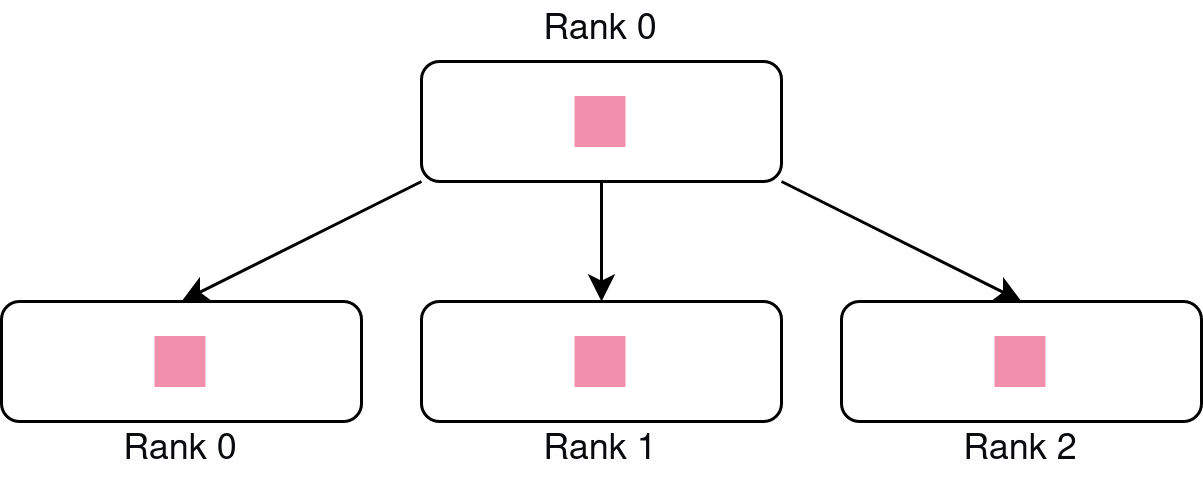
Scatter: A list of tensors is scattered to all processes in the process group.
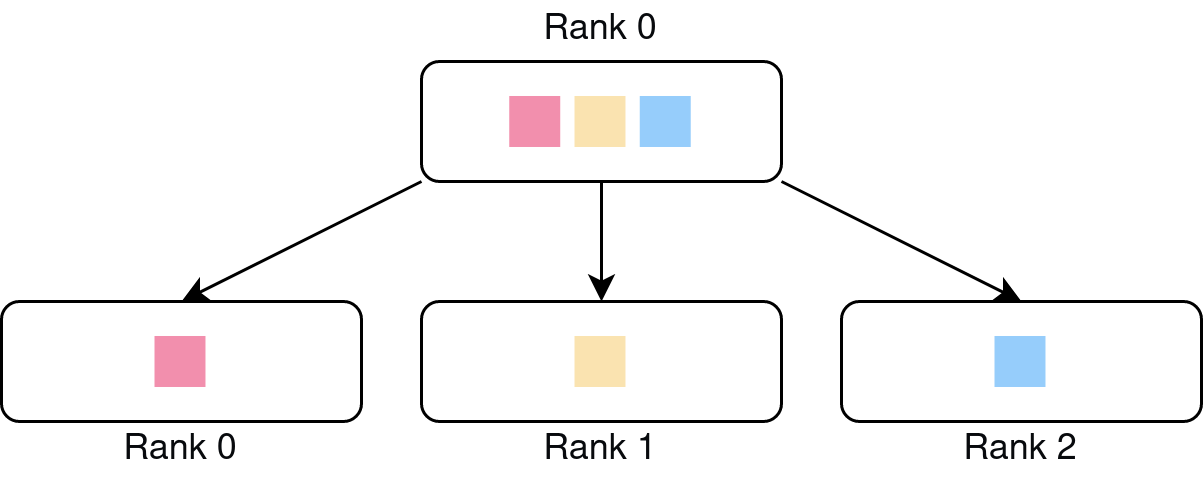
Gather: Gathers a list of tensors, one from each process, into a destination process.
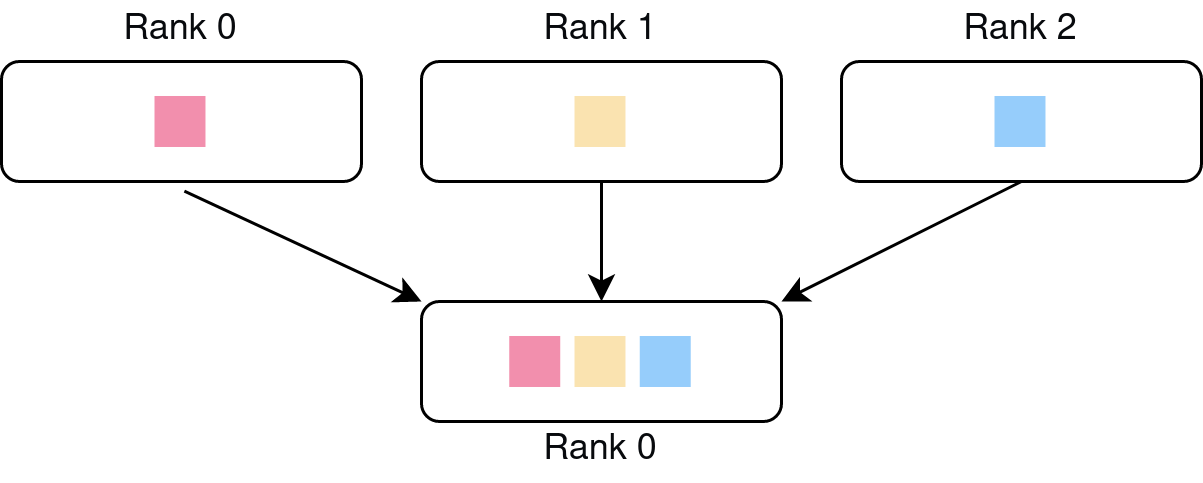
Reduce: Reduces a list of tensors, one from each processes, into a single tensor on a destination process. The figure below shows the case when the reduction operation is addition.
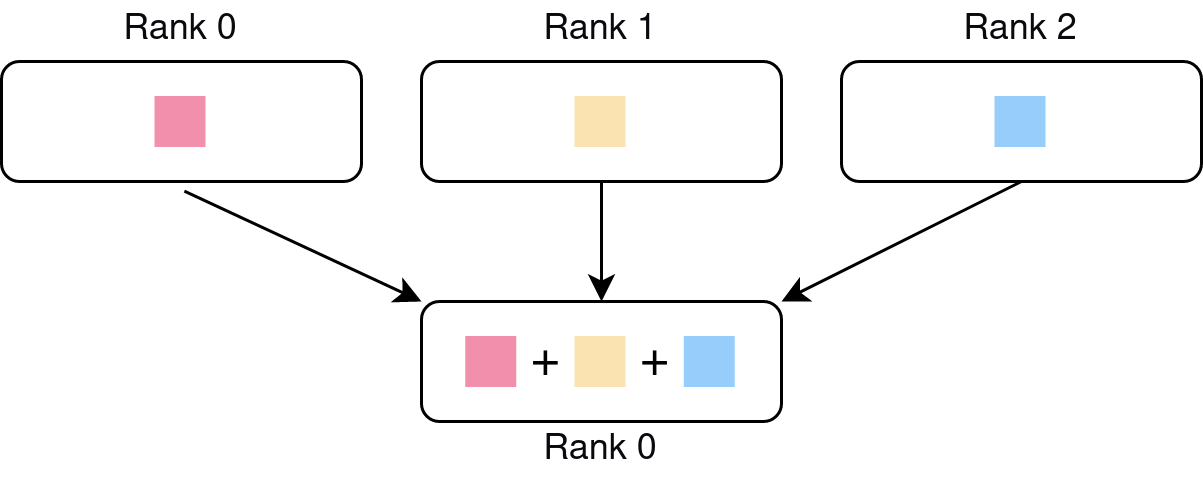
All-gather: Performs an all-gather operation among all processes in the process group.
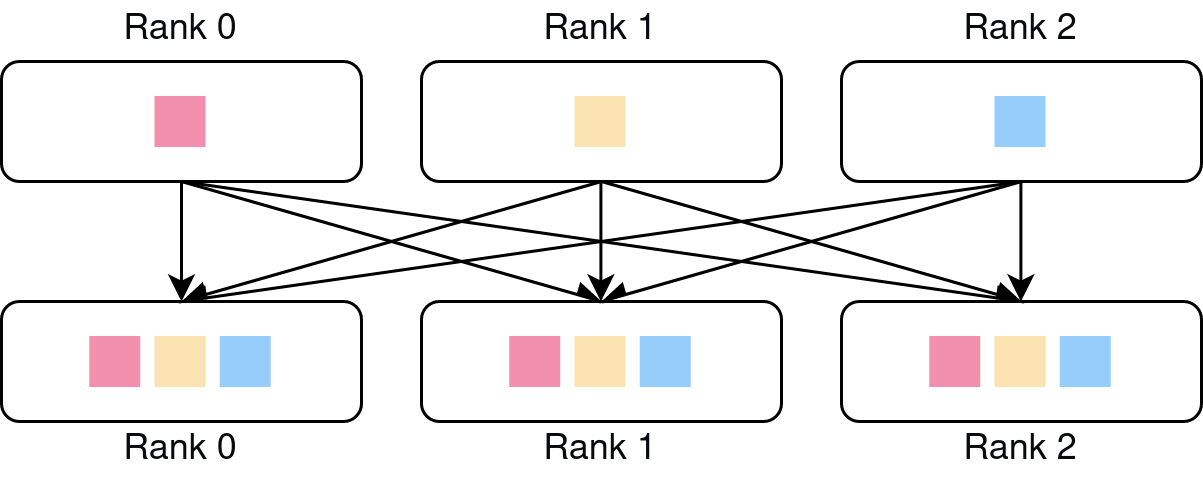
All-reduce: Performs reduction across all processes in the process group.
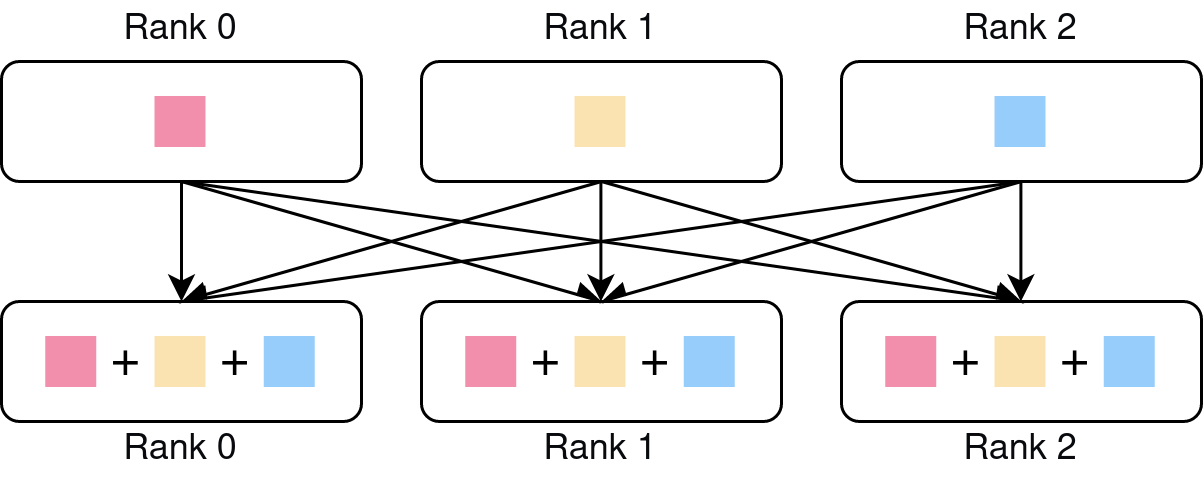
torch.distributed supports all of these collective operations, and more.
For example, let’s write the training part of a distributed training application.
import torch
import torch.distributed as dist
...
def main(rank, size):
# Init process group
dist.init_process_group('gloo', rank=rank, world_size=size)
# Manual seed to make sure all processes start with the same model
torch.manual_seed(1337)
net = torch.nn.Linear(10, 1)
loader = get_dataloader()
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
for epoch in range(10):
for X, y in loader:
y_pred = net(X)
loss = loss_fn(y_pred, y)
# All-reduce
for p in net.parameters():
dist.all_reduce(p.grad.data, op=dist.ReduceOp.SUM)
p.grad /= size
optimizer.step()
The all-reduce operation is used to synchronize updates across all processes. We used the SUM operation in this case, then divide the gradients by the world size to get the average gradient. dist.ReduceOp supports SUM, AVG, PRODUCT, MIN, MAX, BAND, BOR, and BXOR operations out of the box. BAND, BOR, and BXOR are not available for NCCL backend, and AVG is only available for NCCL backend; thus we did not use AVG in this example.
This is, however, just a naive implementation. DistributedDataParallel is much more well-optimized, efficient, and well-tested. We will see how to use it and discuss some of its engineering details in the next article.
Groups
By default, collective communication is performed among the default group, that is the world. For fine-grained control, we can create a group and pass it to the group argument of any of the collective operations.
import torch
import torch.distributed as dist
...
# World size 4
def main(rank, size):
dist.init_process_group('gloo', rank=rank, world_size=size)
group = dist.new_group(ranks=[0, 1])
tensor = torch.randn(4, 4)
# Call all-reduce on this group only
dist.all_reduce(tensor, group=group, op=dist.ReduceOp.SUM)
print(tensor.sum())
tensor(-0.6806)
tensor(-0.6806)
tensor(0.6597)
tensor(-1.3549)
The all_reduce op was called on the group of rank 0 and 1, thus after the reduction, tensors of these 2 processes have the same value (thus the same sum).
Closing remarks
This much about distributed communication should be enough to get you started! For more resources, check out the module documentation and PyTorch’s writing distributed application tutorial.
See you the next article where we will dive into the magic of DistributedDataParallel!
